Chapter 3 Build Analytics
3.1 Motivation
3.1.1 Introduction
Ideally, when building a project from source code to executable, the process should be fast and error-free. Unfortunately, this is not always the case and automated build systems notify developers of compile errors, missing dependencies, broken functionality and many other problems. This chapter is aimed to give an overview of the effort made in build analytics field and Continuous Integration (CI) as an increasingly common development practice in many projects.
3.1.2 Continuous Integration and Version Control System
Continuous Integration in a term used in software engineering to describe a practice of merging all developer working copies to a shared mainline several times a day. CI is in general used together with Version Control System (VCS), an application for revision control that ensures the management of changes to documents, source code and other collections of information.
3.1.3 Build Analytics Definition
Build analytics covers research on data extracted from a build process inside a project. This contains among others, build logs from Continuous Integration such as Travis CI4, Circle CI5, Jenkins6, AppVeyor7 and TeamCity8 or surveys among developers about their usage of Continuous Integration or build systems. This information is often paired with data from Version Control Systems such as Git.
3.1.4 Research Questions
We aimed to make a complete overview of build analytics field by analyzing both state of the art and state of practice. We also inspect the future research that could be done and finally conclude our survey with the research questions that emerged after this exhaustive field research. To achieve a structured way of summarizing the field, we asked the following research questions:
RQ1: What is the current state of the art in the field of build analytics?
In section 3.3.1 we present the current topics that are being explored in the build analytics domain alongside the research methods, tools and datasets acquired for the problems at hand and aggregate and reflect about the main research findings that the state-of-the-art papers display.
RQ2: What is the current state of practice in the field of build analytics?
Section 3.3.2 examines scientific papers to analyze the current trend of build analytics in the software development industry. We look at the popularity of CI in the industry and explore the increase in the use of CI by discussing its ample benefits. Furthermore, we will discuss the practices used by engineers in the industry to ensure that their code is improving and not decaying.
RQ3: What future research can we expect in the field of build analytics?
In section 3.3.3 we will explore where new challenges lie in the field of build analytics. We will also show what open research items are described in the papers. This section ends with research questions based on the open research and challenges in current research.
3.2 Research Protocol
3.2.1 Search Strategy
Taking advantage of the initial seed consisting of Bird and Zimmermann[28], Beller et al. [24], Rausch et al. [160], Beller et al. TravisTorrent [25], Pinto et al. [149], Zhao et al. [200], Widder et al. [193] and Hilton et al. [86], we used references to find new papers to analyze. Moreover, we used academical search engine Google Scholar to perform a keyword-based search for other relevant build analytics papers. The keywords used were: build analytics, machine learning, build time, prediction, continuous integration, build failures, active learning, build errors, mining, software repositories, open-source software.
3.2.2 Selection Criteria
In order to provide a valid current overview of the build analytics field, we selected only the relevant papers that were published after 2008, in other words we have not included papers older than 10 years. We had chosen 10 years as our threshold inspired by the “ICSE-Most Influential Paper 10 Years Later” Award. The only paper that does not conform to this rule is the cornerstone description of CI practices written by Martin Fowler, as we considered it important for us to see the practices evolution in build analytics field. Most of the papers we founded were linked to our research questions as references in the sections bellow. From the selected papers, we omitted two papers, as they are small case studies on a couple of projects and do not introduce new techniques or applications.
See table 10.1 for an overview of the papers which were selected for this survey.
3.3 Answers
3.3.1 Build Analytics State of the Art
RQ1: What is the current state of the art in the field of build analytics?
The current state-of-the-art in the build analytics domain refers to the use of machine learning techniques to increase the productivity when using Continuous Integration (CI), to generate constraints on the configuration of the CI that could improve build success rate and to predict build failures even for newer projects with less training data available.
The papers identified using the research protocol defined in section 3.2 that give us an overview of the current state of the art in build analytics field are:
- HireBuild: an automatic approach to history-driven repair of build scripts [82]
- A tale of CI build failures: An open source and a financial organization perspective [188]
- (No) Influence of Continuous Integration on the Commit Activity in GitHub Projects [12]
- Built to last or built too fast?: evaluating prediction models for build times [30]
- Statically Verifying Continuous Integration Configurations [166]
- ACONA: active online model adaptation for predicting continuous integration build failures [140]
The topics that are being explored are:
- the importance of the build process in a VCS project in reference [82]
- the impact factors of user satisfaction for using a CI tools in reference [193]
- methods from helping the developer to fix bugs in references [82], [187]
- predicting build time in reference [30]
- predicting build failures in references [166], [140]
The tools that are being proposed are:
- BART to help developers fix build errors by generating a summary of the failures with useful information, thus eliminating the need to browse error logs [187]
- HireBuild to automatically fix build failures based on previous changes [82]
- VeriCI capable of checking the errors in CI configurations files before the developer pushes a commit and without needing to wait for the build result [166]
- ACONA capable of predicting build failure in CI environment for newer projects with less data available [140]
3.3.1.1 Importance of the Build Process and CI Users Satisfaction
The build process is an important part of a project that uses VCS – in the sense that findings by Hassan et al. [82] suggest that for such projects 22% of code commits include changes in build script files for building purposes. Moreover, recent studies have focused on how satisfied the users of CI tools are. One paper by Widder et al. [193] analyzed which factors have an impact on abandonment of Travis CI. This paper finds that increased build complexity reduces the chance of abandonment, but larger projects ared abandoned at a higher rate and that a project’s language has significant but varying effect. A surprising result is that metrics of configuration attempts and knowledge dispersion in the project do not affect its rate of abandonment.
3.3.1.2 Patent for Predicting Build Errors
In [28], Bird et al. introduce a method for predicting software build errors. This US patent is owned by Microsoft. Having logistic regression as machine learning technique, the patent describes how to compute the probability of a build to fail. Using this method, build errors can be better anticipated, which decreases the time between working builds and speeds up development.
3.3.1.3 Predicting Build Time
Another important aspect is the impact of CI on the development process efficiency. One of the papers that addresses this matter is written by Bisong et al. [30]. This paper aims to find a balance between the frequency of integration and developer’s productivity by proposing machine learning models that were able to predict the build outcome. For this, they took advantage of the 56 features presented in the TravisTorrent build records. Their models performed quite well with an R-Squared of around 80%, meaning that they were able to capture the variation of build time over multiple projects. Their research could be useful on one hand for software developers and project managers for a better time management scheme and on the other hand, for other researchers that may improve their proposed models.
3.3.1.4 Predicting Build Failures
Moreover, usage of automation build tools introduces a delay in the development cycle generated by the waiting time until the build finish successfully. One of the most recent analyzed papers by Santolucito et al. [166] presents a tool VeriCI capable of checking the errors in CI configurations files before the developer pushes a commit and without needing to wait for the build result. This paper focuses on prediction of build failure without using metadata such as number of commits, code churn also in the learning process, but relying on the actual user programs and configuration scripts. This fact makes the identification of the error cause possible. VeriCI achieves 83% accuracy of predicting build failure on real data from GitHub projects and 30-48% of time the error justification provided by the tool matched the actual error cause. These results seem promising, but there is a need to focus more on producing the error justification fact that could make the use of machine learning tools in real build analytics tools achievable and tolerated.
3.3.1.5 Prediction with Less Data Available
Even if there were considerable efforts in developing powerful and accurate machine learning models for predicting the outcome of builds, most of these techniques cannot be trained properly without extensive historical project data. The problem that resulted from this is that newer projects are unable to take advantage of the research conducted before and have to wait until enough data from their project is generated to sufficiently train machine learning models for predicting the build outcome. In reference [140], the most recent paper of this survey which was published as a poster in June 2018, Ni et al. address the problem of build failure prediction in CI environment for newer projects with less available data. They are using already trained models from other projects with more data available and combined them by means of active learning to find which of these models generalized better from the problem at hand and to update the model’s weights accordingly. They also aim to cut the expense that CI introduces by reducing the label data necessary for training. Even if the method seems promising, the results presented in the poster show an F-Measure (harmonic average of recall and precision) of around 40% that one might are argue should be higher to be truly useful in practice.
3.3.2 Build Analytics State of Practice
RQ2: What is the current state of practice in the field of build analytics?
Continuous Integration is a software engineering practice that requires developers to integrate code into a shared repository several times a day. Each check-in is then verified by an automated build which allows engineers to detect bugs early.
An overview of Continuous Integration evolution from the introduction of the term to the current practices can be seen in the figure bellow:
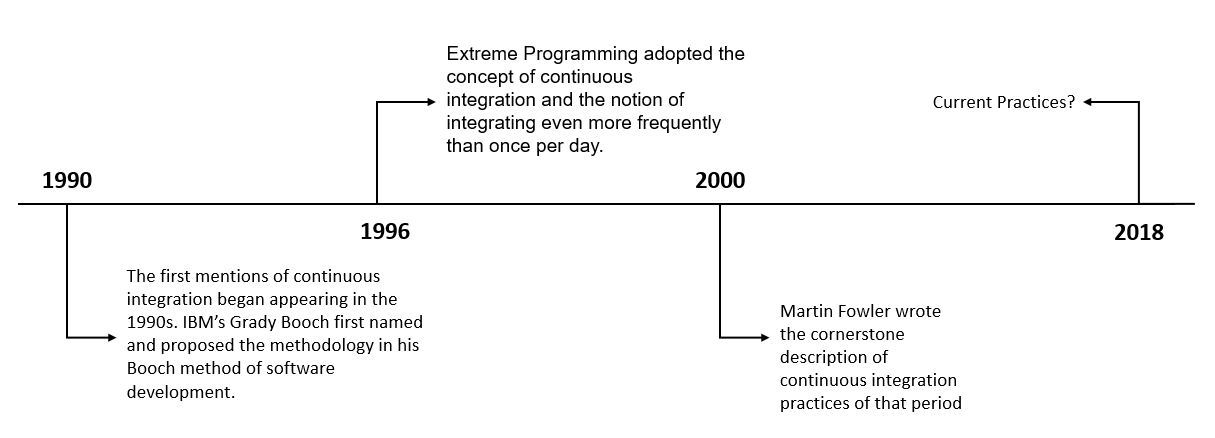
CI overview.
The papers identified using the research protocol defined in section 3.2 that give us an overview of the current state of the art in build analytics domain are:
- Usage, Costs, and Benefits of Continuous Integration in Open-Source Projects [86]
- An Empirical Analysis of Build Failures in the Continuous Integration Workflows of Java-Based Open-Source Software [160]
- Continuous Integration [68]
- Enabling Agile Testing Through Continuous Integration [176]
- TravisTorrent: Synthesizing Travis CI and Github for Full-Stack Research on Continuous Integration [25]
- I’m Leaving You, Travis: A Continuous Integration Breakup Story [193]
- Continuous integration in a social-coding world: Empirical evidence from GITHUB [186]
The topics that are being explored are:
- Usage of CI in the industry by [86]
- Growing popularity of CI due to the introduction of VCS as suggested by [160]
- Common practices used in the industry exemplified by [68]
- Use of common CI practice in the agile approach presented by [176]
- Comparison between pull requests and direct commits to result in successful build as uncovered by [186]
3.3.2.1 Build Analytics Usage
A survey conducted in open-source projects by Hilton et al. [86] indicated that 40% of all projects used CI. It observed that the average project introduces CI a year into development. Furthermore, the paper claims that CI is widely used in practice nowadays. One of many factors contributing to this is explored by Rausch et al. [160]. The growing popularity of Version Control Systems (VCS) such as Git, and hosting build automation platforms such as Travis have enabled any business of size to adopt the CI framework. As suggested by Hilton et al. [86], the cost and time associated with introducing the CI framework is not enormous and the copious benefits far outweigh the resources required.
3.3.2.2 Build Analytics Practices
The CI concept, often attributed to Martin Fowler [68], is recommended as best practice of agile software development methods such as extreme Programming [176]. Fowler introduced many practices that are essential in maintaining the CI framework. Fowler and Foemmel [68] urge engineers to keep all artifacts required to build the project in a single repository. This ensures that the system does not require additional dependencies. In addition, they advise to create a build script that can compile the code, execute unit tests and automate integration. Once the code is built, all tests should run to confirm that the built artifact behaves as the developer would expect it to behave. In this way, we are finding and eradicating software bugs earlier and keeping builds fast. As explored by Widder et al. [193], one of the factors that lead to companies abandoning the CI framework is the complexity of the build. A good practice is to have more fast-executing tests than slow tests.
Furthermore, builds should be readily available to stakeholders and testers as this can reduce the amount of rework required when rebuilding a feature that does not meet the requirements. In general, all companies should (at least) schedule a “nightly build” to update the project from the repository to ensure everyone is up to date. Continuous Integration is all about communication, so it is important to ensure that everyone can easily see the current state of the system. This is also another reason why CI works well in the agile industry [176]. Both techniques stress the importance of good communication.
The paper by Vasilescu et al. [186] studies a sample of large and active GitHub projects developed in Java, Python and Ruby. The paper finds that direct code modifications (commits) are more popular than indirect code modifications (pull request). Additionally, the notion of automated testing is not as widely practiced. Most samples in Vasilescu’s study [186] were configured to use Travis CI, however, less than half actually did use it. In terms of languages, Ruby projects are among the early adopters of Travis CI, while Java projects are late to adopt CI. The paper uncovers that the pull requests are much more likely to result in successful builds than direct commits.
3.3.3 Build Analytics Future Research
RQ3: What future research can we expect in the field of build analytics?
Currently research on build analytics is limited by some challenges, some are specific to build analytics and some are applicable to the entire field of software engineering.
The papers identified using the research protocol defined in section 3.2 that give us an overview of challenges and future research in the field of build analytics are:
- Built to last or built too fast?: evaluating prediction models for build times [30]
- Work Practices and Challenges in Continuous Integration: A Survey with Travis CI Users [149]
- Statically Verifying Continuous Integration Configurations [166]
- (No) Influence of Continuous Integration on the Commit Activity in GitHub Projects [12]
- The impact of continuous integration on other software development practices: a large-scale empirical study [200]
- Un-Break My Build: Assisting Developers with Build Repair Hints [187]
- Oops, my tests broke the build: An explorative analysis of Travis CI with GitHub [24]
In Bisong et al. [30] the main limitation was the performance of the machine learning algorithm used. In the R implementation was used and it proved not capable of processing the amounts of data needed. This shows that it is important to choose the right tool when analyzing data.
In Pinto and Rebouças[149] it is noted that research is often done on open source software. There are still a lot of possibilities for researching on proprietary software projects.
Tools presented in papers might require a more large-scale and long-term study to verify that the tool presented keeps up when it is used [166].
Future research in build analytics branches in a couple of different topics. Pinto and Rebouças [149] proposes to focus on getting a better understanding of the users and why they might choose to abandon an automatic build platform.
Baltes et al. [12] suggest that in future research more perspectives when analyzing commit data should be considered, for instance partitioning commits by developer. They also note the importance of more qualitative research.
Some open research questions from recent papers are the following:
- How do teams change their pull request review practices in response to the introduction of continuous integration? [200]
- How can we detect if fixing a build configuration requires changes in the remote environment? [187]
- Does breaking the build often translate to worse project quality and decreased productivity? [24]
- Could already trained models on projects with more data available be used to make accurate predictions on newer projects with less data available? [140]
From the synthesis of the works discussed in this section the following research questions emerged:
- What is the impact of the choice of Continuous Integration platform? Most of the research is done on users using Travis CI, there are many other platforms out there. Every platform has their own characteristics and this could impact the effectiveness for a specific kind of project.
- How does the platform or programming language influence effectiveness or adoption of continuous integration systems?
- How can machine learning methods be better applied in the field of build analytics in order to generate predictions that are easier to explain and thus can be used in practice?
References
[28] Bird, C. and Zimmermann, T. 2017. Predicting software build errors. Google Patents.
[24] Beller, M. et al. 2017. Oops, my tests broke the build: An explorative analysis of travis ci with github. Mining software repositories (msr), 2017 ieee/acm 14th international conference on (2017), 356–367.
[160] Rausch, T. et al. 2017. An empirical analysis of build failures in the continuous integration workflows of java-based open-source software. Proceedings of the 14th international conference on mining software repositories (2017), 345–355.
[25] Beller, M. et al. 2017. Travistorrent: Synthesizing travis ci and github for full-stack research on continuous integration. Proceedings of the 14th international conference on mining software repositories (2017), 447–450.
[149] Pinto, G. and Rebouças, F.C.R.B.M. 2018. Work practices and challenges in continuous integration: A survey with travis ci users. (2018).
[200] Zhao, Y. et al. 2017. The impact of continuous integration on other software development practices: A large-scale empirical study. Proceedings of the 32nd ieee/acm international conference on automated software engineering (2017), 60–71.
[193] Widder, D.G. et al. 2018. I’im leaving you, travis: A continuous integration breakup story. (2018).
[86] Hilton, M. et al. 2016. Usage, costs, and benefits of continuous integration in open-source projects. Proceedings of the 31st ieee/acm international conference on automated software engineering (2016), 426–437.
[82] Hassan, F. and Wang, X. 2018. HireBuild: An automatic approach to history-driven repair of build scripts. Proceedings of the 40th international conference on software engineering (2018), 1078–1089.
[188] Vassallo, C. et al. 2017. A tale of ci build failures: An open source and a financial organization perspective. Software maintenance and evolution (icsme), 2017 ieee international conference on (2017), 183–193.
[12] Baltes, S. et al. 2018. (No) influence of continuous integration on the commit activity in github projects. arXiv preprint arXiv:1802.08441. (2018).
[30] Bisong, E. et al. 2017. Built to last or built too fast?: Evaluating prediction models for build times. Proceedings of the 14th international conference on mining software repositories (2017), 487–490.
[166] Santolucito, M. et al. 2018. Statically verifying continuous integration configurations. arXiv preprint arXiv:1805.04473. (2018).
[140] Ni, A. and Li, M. 2018. ACONA: Active online model adaptation for predicting continuous integration build failures. Proceedings of the 40th international conference on software engineering: Companion proceeedings (2018), 366–367.
[187] Vassallo, C. et al. 2018. Un-break my build: Assisting developers with build repair hints. (2018).
[68] Fowler, M. and Foemmel, M. 2006. Continuous integration. Thought-Works) http://www. thoughtworks. com/Continuous Integration. pdf. 122, (2006), 14.
[176] Stolberg, S. 2009. Enabling agile testing through continuous integration. Agile conference, 2009. agile’09. (2009), 369–374.
[186] Vasilescu, B. et al. 2014. Continuous integration in a social-coding world: Empirical evidence from github. Software maintenance and evolution (icsme), 2014 ieee international conference on (2014), 401–405.